 MySQL 数据库优化:用最简单但最有效的方法搞懂它
MySQL 数据库优化:用最简单但最有效的方法搞懂它
MySQL 数据库优化:用最简单但最有效的方法搞懂它
MySQL 数据库优化:用最简单但最有效的方法搞懂它

在软件开发的生命周期里,你总会遇到一个时刻——
“数据库是不是该优化一下了?”
我在电商行业干了 15 年,大促、活动、跨国业务扩张、读写分离延迟……
经历了一轮又一轮性能瓶颈。
这一篇文章,就是把我踩过的坑、做过的优化,按最朴素的方式讲清楚。
其实数据库优化没有你想得那么玄乎,都是一个个很小的步骤,但整个优化过程就是围绕这些点来展开。
你可能遇到:
主库压力过大?
QPS 快顶不住?
活动大促要来了?
要扩展到新业务 / 新国家?
主从同步有延迟?
不同系统可能有不同触发点,但优化方向基本都离不开下面这几个。
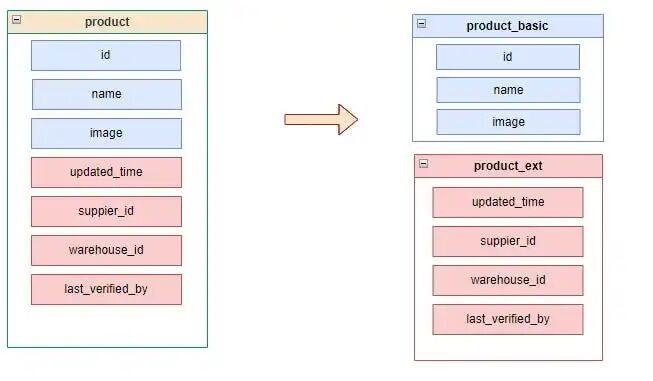
先弄清楚你主库里都放了什么表:
静态表(变化不频繁,如商品基础信息)
动态表(写入频繁,如库存、价格、订单)
电商里常见场景:
供应商会不断更新“价格”和“库存”,这些表会被不断写入。
如果所有表混在一个库里,那么:
动态表的写入压力
可能会拖慢静态表的查询
因此,你应该考虑:
✔ 把静态和动态的表拆成不同库
✔ 把分析类 SQL(报表、BI)放到单独的库或专用从库
这样不会互相影响。

我们很多系统喜欢把历史数据全堆在主库里,想着“以防万一”。
但这会带来:
数据越多
→ 行越多
→ 查询越慢
→ 索引越大
→ CPU / IO 压力更高
解决方式:
✔ 把历史数据定期归档
✔ 主库只保留业务需要的“在线数据”
✔ 历史数据按需访问(如独立归档库)
这样主库会“轻松很多”。
SQL 优化永远是第一生产力。
优化可以在:
应用层(ORM、SQL 写法)
数据库层(索引、执行计划)
这些技巧网上一大堆,我就不重复,但一定要记住:
✔ 坏 SQL 是性能杀手
✔ 线上慢查询一定要持续监控
✔ 索引不是越多越好,要“用得上”才加
MySQL 官方文档都有详细教程。
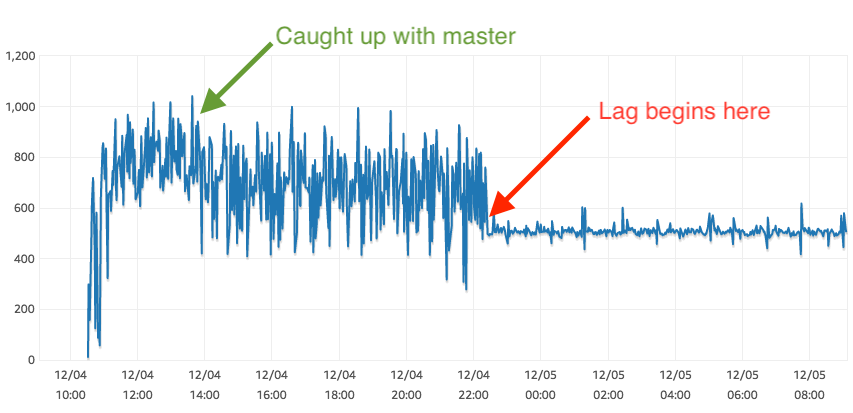
大部分系统都是:
主库写
从库读
但主从同步有可能出现延迟(master → slave 复制慢)。
常见原因:
慢 SQL 堵住 binlog
高并发写入
slave IO / CPU 不够
大事务
你可以:
✔ 打开慢查询日志,找出“罪魁祸首”
✔ 使用 GTID 同步模式(更稳定、更自动化)
GTID 会自动标记每个事务,能减少很多从库重启、重新同步的麻烦。
很多人上线数据库后就从不调参数。
但 MySQL 默认配置不一定适合线上业务。
你需要关注:
看看缓存是否合适,命中率怎样。
InnoDB 的核心参数。内存够大就调大,让更多数据能放进内存。
越大越适合大表,但不建议轻易改,更多是理解概念。
简单讲:
✔ 足够的内存
✔ 合理的 buffer pool
✔ 避免不必要的 query cache
性能会明显提升。
举个例子:
mysql> show variables like ‘query_cache_size’;
+ — — — — — — — — — + — — — — -+
| Variable_name | Value |
+ — — — — — — — — — + — — — — -+
| query_cache_size | 1048576 |
+ — — — — — — — — — + — — — — -+
1 row in set (0.00 sec)
mysql> SHOW STATUS LIKE “qcache%”;
+ — — — — — — — — — — — — -+ — — — — -+
| Variable_name | Value |
+ — — — — — — — — — — — — -+ — — — — -+
| Qcache_free_blocks | 1 |
| Qcache_free_memory | 1031320 |
| Qcache_hits | 0 |
| Qcache_inserts | 0 |
| Qcache_lowmem_prunes | 0 |
| Qcache_not_cached | 1 |
| Qcache_queries_in_cache | 0 |
| Qcache_total_blocks | 1 |
+ — — — — — — — — — — — — -+ — — — — -+
8 rows in set (0.01 sec)


不是每个系统都需要分区!
但如果你的表特别大,按某个维度切分可以加快查询。
例如:
按月分区(YYYYMM)
按日期分区(YYYYMMDD)
按业务字段分区(如商家 ID)
分区的好处:
✔ 提高查询速度
✔ 更容易归档
✔ 单个分区更“小”,操作更快
但分区不是银弹,要谨慎设计。
如果你的系统有:
多个从库
复杂读写分离
分库分表
查询路由需求
那么 ProxySQL 就很有用。
它可以:
✔ 做 SQL 负载均衡
✔ 动态切换主从
✔ 做 SQL 路由(发到不同库/表)
✔ 配合分片(Sharding)
可以理解为:
“数据库的 Nginx”
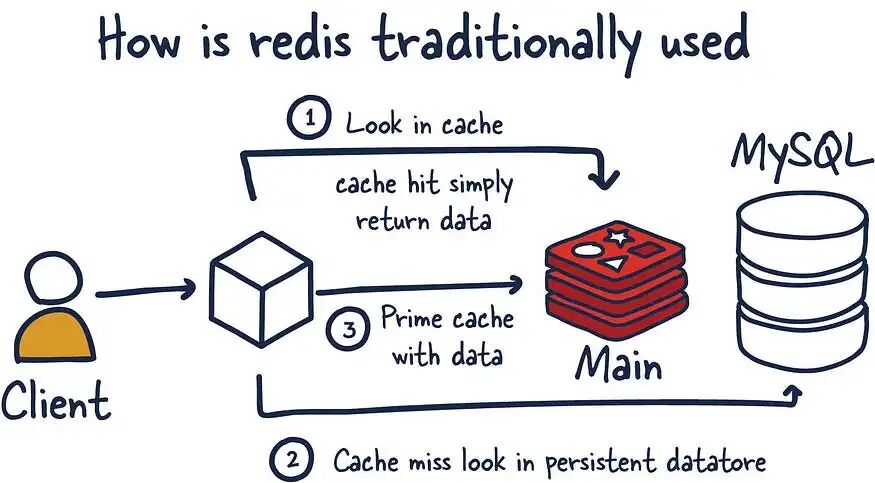
如果数据库已经优化到极限,但业务还是吃不消,就要从架构角度下手。
把常用的数据缓存起来,减少对数据库的依赖。
把写请求用队列“削峰填谷”,避免瞬时写爆主库。
适用技术:
Redis
RabbitMQ
Kafka
AWS SQS
这种架构是大型系统的标配。
如果你使用自建数据库,可能需要:
换更好的 CPU
更快的 SSD / NVMe
调整 IO 能力
调整实例规格(如 AWS EC2)
如果用 RDS,可以选择更高规格的实例类型。
总结一句:
✔ 当你能靠钱解决问题时,不妨用钱
(但别一上来就砸钱)
不监控,就等着踩坑。
常见的监控:
Percona Monitoring
Zabbix
DataDog
Prometheus + Grafana
阿里云 RDS 自带监控
你能看到:
✔ 慢查询
✔ QPS/TPS
✔ 主从延迟
✔ Buffer Pool 命中率
✔ 连接数
✔ CPU / IO 使用率
这才是真正让你安心的方式。
数据库优化、调优、扩展,是三个不同概念:
优化(Optimization):让 SQL/表结构更合理
调优(Tuning):调整参数、配置
扩展(Scaling):升级架构或硬件
这篇文章只覆盖了我亲身实践过、并且效果非常明显的部分。
数据库没有“万能解法”,
只有——
在这个信息爆炸的时代,家长们都希望自己的孩子能够健康成长,但不少家庭...
你是否曾在计划港澳之行时,为办理港澳通行证而感到困扰?别担心,专家/...

电视机出现花屏是怎么回事?1、液晶屏故障:一般原因都是屏幕受到敲击...

怎么正确使用发光化妆镜?局部放大:利用化妆镜的放大功能仔细观察眼部...

它们在内蒙古自治区共同设立了国有地方城市商业银行。公司于2020...
